

Analyzing Recurrent Neural Networks (RNNs) Using Chemical Dynamics Theory
Jupyter notebook poc_rnn_polymer.ipynb

Jupyter notebook poc_rnn_polymer.ipynb
Summary
As an amateur scientist, I analyze the dynamics of Long Short-Term Memory (LSTM) elements when applied to strings of characters. I show how the terminal padding characters have a relatively small impact on the dynamics of an LSTM element. In contrast, the initial non-padding characters have large impacts on the LSTM element dynamics. I attempt to relate this behavior to concepts I’m familiar with in Brownian and ballistic dynamics of polymer statistical mechanics (i.e., chemical networks theory).
I’ll admit I’m a novice in these areas and other experts could possibly do more with these methods. Further, it’s possible RNNs have been analyzed in similar fashions before. If so, let me know if what previous work I should be citing here. I’d be excited if this becomes a tutorial for people who want to study RNNs in a similar fashion in the future.
Update: Reddit user real_kdbanman user has suggested the work of Tishby et al (paper) as being highly related to this work in that the authors connect the training of nueral networks to concepts from statistical mechanics, including nonequilibrium statistical mechanics. Asking Prof. Tishby if he’s aware of work similar to present work here, which focuses on the dynamics of applying trained models.
Introduction
Recurrent neural networks (RNNs) are an interesting class of neural networks that can be applied to a sequence of inputs and they demonstrate dynamics in processing such sequences. RNNs have been described as approximations of programs — with Turing-complete properties — versus basic neural networks that more readily approximate simpler mathematical functions. More details can be found in Andrej Karpathy’s excellent blog post, “The Unreasonable Effectiveness of Recurrent Neural Networks”.
In this work, the dynamics of one class of RNNs, long short-term memory (LSTM), are studied in the context of translating human-language dates into a standard machine-readable format. This work builds off the excellent example of using RNNs for interpreting dates in varied human formats by Zafarali Ahmed in keras-attention. E.g., converting “November 5, 2016” to “2016–11–05”. I’m simply studying the structure of the RNN used in that work.
I focus on the 512 encoder units within the LSTM layer. I treat each encoder as a linear polymer chain growing in 1-dimension. The dynamics are explored for each encoder unit for different input strings. The RMS velocity autocorrelation function for each encoder unit is computed to quantify the encoders dynamics over a sample of input strings.
The main result is that most encoders show “boring” dynamics, but a few show interesting dynamics with similar, but varied RMS velocity autocorrelation function shape. I attempt to explain these dynamics using concepts I vaguely remember from nonequilibrium statistical mechanics of polymers. (I’m a little ashamed to have forgotten so much from my undergrad and grad studies in these specific areas.) See the Discussion section at the end of the post for more details.
Methods and Results
Using the RNN trained in keras-attention, I analyze the dynamics of each LSTM element in the network. The model is trained to convert human-readable dates into a machine format. Here are some example inputs and outputs:
‘February 16th, 2019’ -> 2019–02–16
‘March the 12th, 2012’ -> 2012–03–03 (note the mistake made by the model)
‘Jan 1 1990’ -> 1990–01–01
‘02–03–1998’ -> 1998–03–02
For the first input string, the dynamics of each LSTM element are roughly shown in the following figure.

There are 512 columns, each corresponding to one LSTM element and 50 rows showing the progression over input sequence characters. A heatmap visualization is used to show the value of each encoder at each point in time. This is a rough visualization and a small sample of encoders will be more thoroughly visualized in the next part of this work.
Following each vertical bar downwards, we can see how the value of each of the 512 LSTM elements evolves with each character in the input sequence. Note all strings are padded to length 50 characters when applying the model using <pad> characters. The horizontal red line shows the sequence input element at which <pad> characters are added to the sequence to fill out the input; i.e., the input string length.
To better show the dynamics of representative example LSTM elements, the following figures show the element values as a function of input sequence element step for a sample of five randomly chosen LSTM elements.
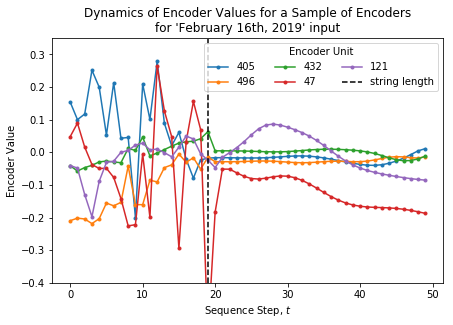
Again, the string length is highlighted.
One interesting attribute of these results is the appearance of smoother transitions shortly after the string length. This suggests that <pad> characters have a relatively smaller impact on the dynamics of each LSTM element than other characters.
Next, the deltas of each example encoders are computed because these tend towards zero with later input steps. The essentially gives us a velocity autocorrelation function with correlation measured with respect to the previous value at each instance in time.
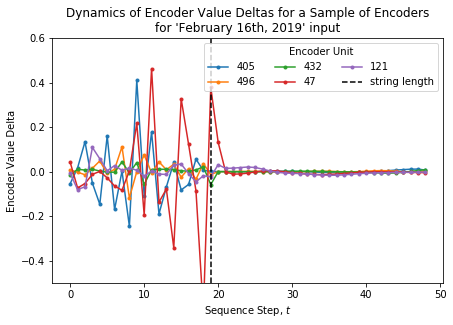
This gives us a time-dependent metric that will tend towards the same terminal value of zero for all input strings and we can now analyze how autocorrelation functions look on average for each encoder unit.
This analysis is repeated for a sample of 1000 strings from a validation set generated in the keras-attention project. The RMS delta of each encoder is computed over these 1000 trajectories and five example RMS functions are shown in the following figure.

One can see that the encoder index 47 shows the most interesting dynamics among these sampled functions. In contrast other encoders such as 432 show less interesting dynamics.
To quantify the extent of interesting dynamics, each encoder RMS function is summed; i.e., taking the area under the curve. The distribution of sum RMS values is shown in the following figure.

The quantiles and other stats of this distribution are:

From these results, we can see that there is a long tail with a small number of encoders having substantially larger sum RMS dynamics. We’d expect these encoders to have the most interesting dynamics and the top five are shown in the following figure.
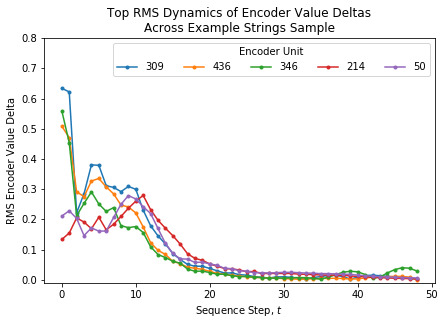
These curves have roughly similar shapes, but there is significant variance in their specific shape. They remind me of velocity autocorrelation functions from physical chemistry theory and I attempt to interpret these similarities in the Discussion section.
Lastly, the dynamics of the most interesting and dynamic encoder, encoder index 309, are shown in the following figure for all 1000 input strings.
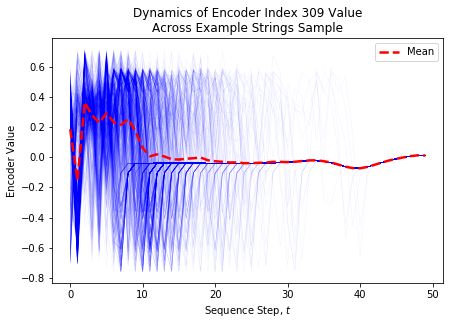
Each blue curve corresponds to a single trajectory for one input sequence and these are rendered highly transparent to show areas with high overlap between multiple trajectories. The dashed solid red curve shows the mean value. We can see that there is a lot of variation in the different trajectories, which shows that different input strings give drastically different dynamics for this one interesting encoder unit. Interesting, this encoder always tends towards a terminal value of zero. It’s still possible the earlier values are useful in the subsequent attention layer of this RNN since it consumes the full sequence for each LSTM element.
Discussion
In this work, I’ve investigated the dynamics of LSTM encoder units on a sample of input strings by treating each encoder as a single linear polymer chain growing in one dimension.
Encoders generally show rich and varied dynamics in the early stages; i.e., when consuming the beginning of an input sequence of characters. At later stages, the dynamics are found to stabilize towards a terminal value. This can be explained by most input strings having <pad> characters that fill out the end of each input sequence. It may be reasonable to expect such <pad> characters to have a negligible impact on changing the value of each encoder after sufficient model training.
Interestingly, the majority of encoders have relatively low magnitude dynamics on average as quantified over a sample of input strings. A small number of encoders show larger magnitude dynamics and are visualized in this work. There are some similarities in the shape of these correlation functions at short to intermediate time scales.
The “boring” dynamics at longer time scales is likely explained by the impact of <pad> characters on the dynamics of each encoder. Hence, from a physical chemistry perspective, we could think of each non-<pad> character as being a strong perturbation acting on the state of each encoder. In contrast, the <pad> characters can be thought of as weaker perturbations, although as shown in the example these perturbations still have some impact on the encoder dynamics.
One might imagine the ML model trying to minimize the impact of <pad> characters in deciding the output of character sequence on the final prediction, while still allowing the complex non-linear interactions in the LSTM layer. One might even say the <pad> perturbations look more like random noise in Brownian dynamics whereas the other perturbations are more like strong driving forces that vary with the characters in the input sequence. The RMS velocity autocorrelation functions suggest these <pad> perturbations average out to close to zero when considering a large number of input strings.
Closing Remarks
Seeing as I know very little about RNNs and polymer dynamics, I’d imagine other people could do much more interesting things with these ideas. Further, I don’t know to what extent the results of this work are covered in existing prior work. It’s possible such RNN dynamics have already been quantified in a related fashion. If so, please let me know so I can cite the work properly. I’ll modify this blog post as needed and give you credit for the advice.
You can check my work and build off it using this Jupyter notebook poc_rnn_polymer.ipynb.