

Hierarchical categorization using OpenAI: Methods exposition
A detailed explanation, source code, and data for clustering my Substack comments using OpenAI embeddings and the ChatGPT API

I previously shared a hierarchical categorization of Slow Boring comments. As promised there within, I’ve now redone that project using only my own Substack comments so that I can share a working demo of computing these clusters and generating titles and summaries using the ChatGPT API. This post will walk you through the data and source code.
Code & data: github.com/matthagy/hagy_comment_category_hierarchy
Interactive demo: matthagy.github.io/hagy_comment_category_hierarchy

Comment Data
We begin with comments.csv, a file containing all 610 of my Substack comments.

Each entry is a single comment and includes the content text as well as assorted metadata such as the number of likes.

Of particular interest is the length of each comment body text as measured in AI-encoding tokens (each token being roughly a syllable). Both very short and very long comments could provide little value and will therefore be filtered out.

Vectorization using OpenAI embeddings
In order to compute clusters of alike comments, we first need a method to quantify text similarity. OpenAI provides a particularly powerful method for measuring semantic similarity in their text embeddings. This API takes a piece of text and computes a vector (ie, list of numbers) with 1,536 components. Each vector is analogous to a point in space such that the distance between two vectors quantifies the semantic similarity; a shorter distance corresponds to more alike text.
To illustrate this, let us select one of my comments.
While a windfall-tax-funded subsidy may spur domestic investment in oil and gas production in the short term, I think this approach will only weaken medium and long term investment due to…
We can compare its embedding against that of every other comment to quantify the similarity of each comment pair. The distribution of embedding similarity (inverse of distance) is as follows.
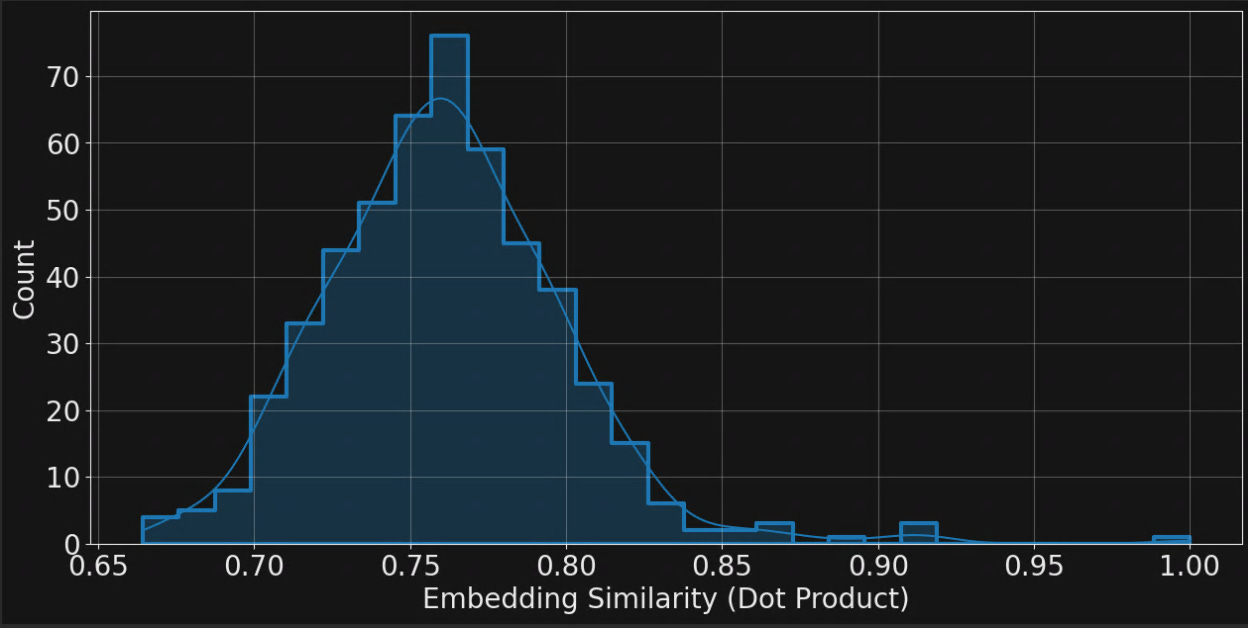
Lets explore some other comments based upon their embedding-quantified similarity against this example. The observation at 1.0 corresponds to the original comment itself. The next highest similarity is 0.91 for the following comment.
Regardless of climate activist actions, I think it will be incredibly difficult to encourage substantially more private investment in domestic oil production and refining projects. I just think that there is too much uncertainty and downside risk as we transition to green energy…
We see that both comments mention the domestic oil and gas industry.
In contrast, the lowest embedding similarity of 0.66 appears to correspond Google’s hiring process; a quite different topic indeed.
I found the following on a quick Bing Chat with “Does the Google internship application process include an online coding test?”
https://careers.google.com/how-we-hire/
…
The script vectorize_comments.py computes the embedding vector for each comment, after filtering out particularly short/long comments.

Hierarchal clustering algorithm
Now that we have a way to quantify the semantic similarity of any pair of comments, we can construct categories of related comments. Specifically, we can use agglomerative clustering to compute a hierarchy of categories. This algorithm starts by assigning every data point to a singleton cluster containing just that one entry. It then iteratively merges the two closest (ie, most similar) clusters using the distance metric provided by the text embeddings. Each merge results in an intermediate cluster with two child clusters. The algorithm is repeated until we have a single top-level cluster.
The result is a binary tree of categories, with “binary” implying that each non-terminal cluster has two child clusters. The structure can be visualized as follows:

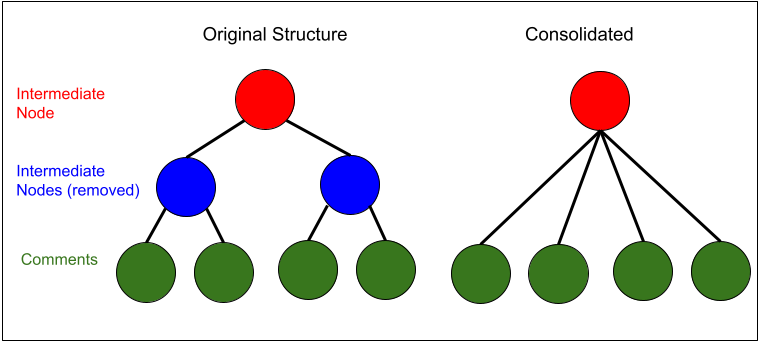
Next, we can simply this binary tree by consolidating (ie, combing) clusters if the comments across them are sufficiently similar. The following diagram shows an example of consolidation where the intermediate blue nodes are eliminated to create a single cluster with four comments.
We simply need to define the criteria for when consolidation should be performed. For that, we consider the root-mean-square dispersion of the embeddings within the candidate consolidation. Ie, how semantically similar are the comments within the new combination as quantified by their embeddings.

Additionally, unnecessary intermediate nodes are eliminated when the new consolidated node would have five or fewer children.
The script cluster.py performs the hierarchical clustering and outputs a tree structure.

This includes printing information about consolidations performed as well as the final tree structure.

ChatGPT generated titles
Now that we have a hierarchy of categories, we can use ChatGPT to help us make sense of the comments within each group. We’ll start by asking the AI to propose a title for each category from a sample of comments. These titles will be used within the interactive visualization to concisely show clustering structure.
First, we need a way to sample comments within a group when the group is sufficiently large because ChatGPT has a limited input window length. Random sampling, with weighting by the number of likes on each comment, is chosen so that higher quality comments are more likely to be sampled.

Next, we need to determine how to present this information to ChatGPT. After some experimentation, the following prompt is found to produce decent results.
Suggest a short, yet descriptive name for the group of similar comments below. Response should be at most 5 words in length. Avoid generic names like "discussion" or "comments". Respond only with the group name, do not provide any explanation, formatting, or punctuation.
Comments:
[comments in a bulleted list]
Interestingly, running this prompt multiple times is commonly found to produce significantly different titles across attempts. For example, here are the titles that ChatGPT suggested across five different runs for a single, constant sample of comments within one group.
"Controversial Leftist Ideology
Commentary on Beliefs and Values.
Internet Atheism
"Provocative Opinions on Society
"Controversial Leftist Ideas"
There is something of a common theme across those titles, but they are still each quite different from each other. In contrast, the following titles for another group are quite consistent.
SVB Collapse Discussion.
SVB Collapse Discussion.
SVB Collapse-related Comments
SVB Collapse Discussions
SVB Collapse Comments
I handle this title variation by requesting five different titles, through five invocations, for each category. The UI will show a single title when displaying the overall hierarchical category structure and the detailed information tab will show all five titles when the group is selected. That allows the user to quickly see when there is title variation.

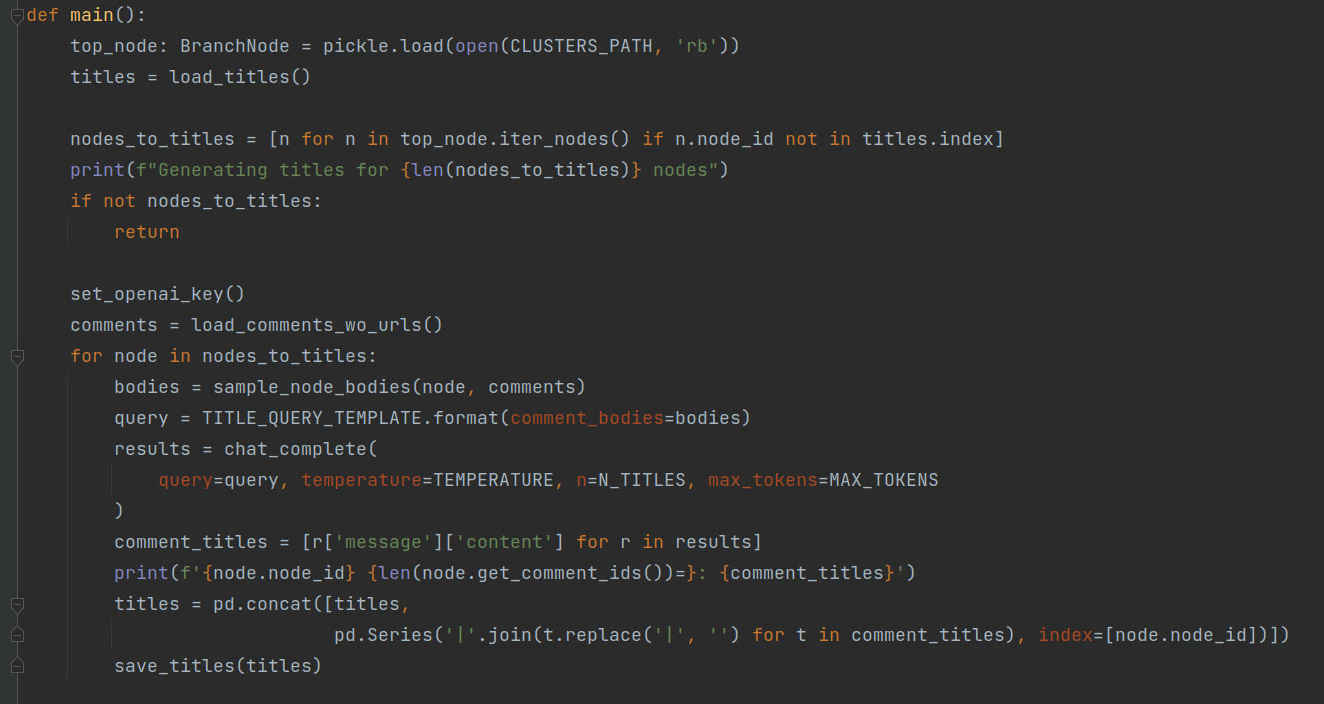
The generate_titles.py script uses the ChatGPT API to apply this prompt to a sample of comments from each group. The results are written to titles.csv.
ChatGPT generated summaries
We’d also like a summary of the comments within each category. Similar to titles, we can asked ChatGPT to help us with this task. The following prompt is found to work well for summarization.
Summarize the group of similar comments from one authors below. Focus on the main themes or viewpoints expressed within the comments. Output one to three paragraphs of text.
Comments:
[comments in a bulleted list]
The script generate_summaries.py applies the ChatGPT API in the same fashion as the titles generation script. Results are written to summaries.csv.
In exploring these summaries of my own comments, I find ChatGPT shockingly accurate in understanding and presenting my own writing. There is something surreal in staring into this AI mirror of my own beliefs and views. Notably, the top-level summary, that being for a sample of all of my comments, is an eerily high-fidelity presentation of how I think and feel about a range of topics.
The comments from this author can be summarized into a few main themes. First, the author expresses concern over the disproportionate amount of power held by liberal and progressive elites within the Democratic party, particularly those in journalism and academia. The author worries that this could push these elites further away from the average Democratic voter and create opportunities for right-wing populists to exploit.
Second, the author provides insights into topics ranging from the decline of atheism on the internet, to the sophistication of comments on various substacks, to the potential of a muscular welfare state to improve capitalism. They also offer recommendations, such as urging readers to check out a Vanity Fair article on the current "thought leadership" of the American right.
Finally, the author provides analysis and suggestions on matters related to policy and finance. For instance, they suggest that the debt ceiling is unconstitutional and that a platinum coin fallback could be a potential solution to prevent global financial meltdown in the event of a judiciary decision against the Treasury. Throughout their comments, the author utilizes precise language and detailed analysis to provide readers with thoughtful insights.
Creating an interactive viewer
We’d now like a tool for viewing the hierarchical structure of these comment categories as well as exploring the titles and summaries for each group. To that end, I’ve created an interactive webpage using TypeScript and D3.js. This part of the project was particularly challenging for me as I have no professional frontend programming experience. I’ve previously expressed my gratitude for ChatGPT and GitHub Copilot in guiding me through these unchartered waters.
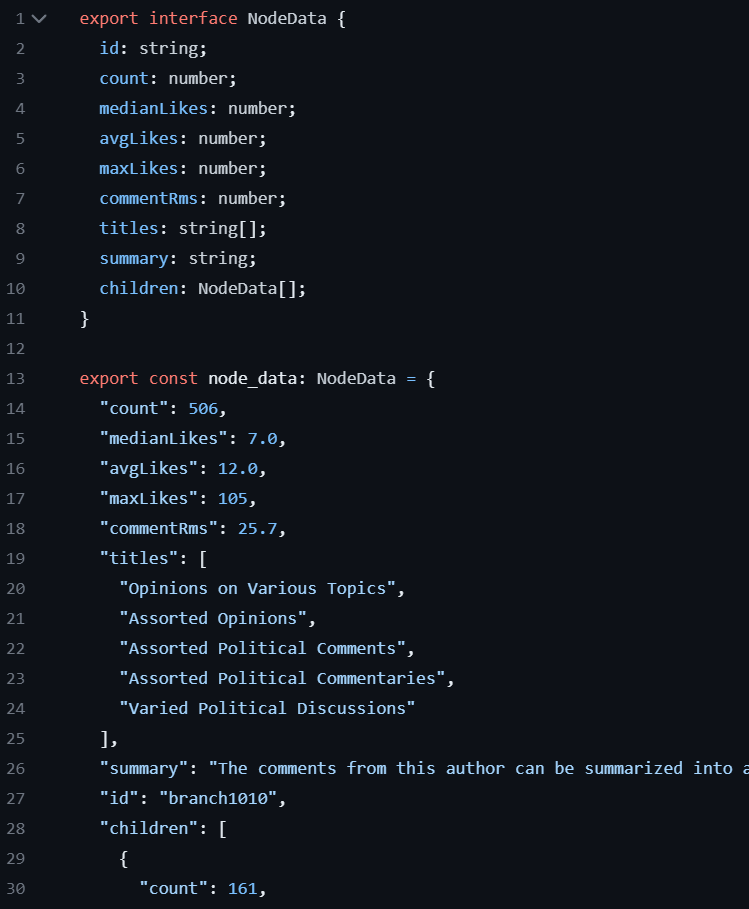
We begin by exporting the categories, including each’s title, summary, and assorted metadata using the script export.py. This generates the file nodes.ts provides the data for visualization.
The interactive visualization is primarily based around the D3.js TreeLayout. This takes the hierarchical category structure and computes an appropriate positioning for each node in a two-dimensional plane. Ie, it determines (x,y) coordinates for each node. Each category is represented by the abstraction HierarchyNode, which provides useful methods for use in rendering.
To render the actual nodes and edges of the tree, we use D3.js data binding. This is powerful concept where a collection of data elements (eg, cluster nodes) can be associated with a companion collection of HTML elements (eg, SVG circles). Our code can then simply focus on the mapping between data and element. For example, positioning each SVG circle for each cluster center using the coordinated provided by the tree layout.

We can also dynamically style each element based upon its companion data.

You can find the full code for this visualization in index.ts. Note that I’m quite the novice with TypeScript and D3.js, so if anything seems odd about this code it is likely just a misunderstanding on my part.
Closing remarks
I hope you’ve found this exposition of hierarchical clustering of text using OpenAI’s embeddings educational. Please let me know if you have any questions or comments.