

Using OpenAI APIs to categorize and label substack comments

OpenAI offers some amazing tools for working with text. Using a combination of their APIs, I found it is easy to categorize (ie, cluster) comments from the Slow Boring substack into 15 categories. This includes asking the ChatGPT API to suggest a name for each category from a sample of comments. The results are quite impressive.

This is accomplished by simply adapting OpenAI’s clustering demo. This post will briefly walk you through my adaptation to substack comments to demonstrate the ease of applying these powerful tools.
To start, substack comments are fetched using the substack_client Python library as I described in a previous post. A random sample of 10,000 comments with moderate length and at least one like are taken for clustering.
The key technology for clustering is OpenAI’s embeddings, which provides a quantitative measure of text similarity. Using the embedding API, each comment is mapped to a vector of 1,536 components. The distance between any two vectors is inversely proportional to similarity. Ie, vectors that are close to each other correspond to comments with similar text. The embeddings are computed using a model that not only captures syntax similarity (ie, words used), but also semantic similarity (ie, topics discussed). This is a sophisticated and powerful tool for working with text, and you can learn more about it in OpenAI’s Dec 2022 blog post, New and improved embedding model.
With this quantitative measure of text similarity, it is trivial to compute clusters of related comments using common methods like k-means clustering. This identifies clusters (ie, groups) of similar comments based upon the embeddings distances. Hence, similar comments are grouped together. This method is applied to the 10,000 substack comment embeddings to generate 15 clusters, with sizes between 330 to 1304 comments. See the Appendix at the end of this post for some clustering details.

Let’s briefly explore some of my comments from each cluster to see what is being grouped together. For the largest cluster, index 0, here are three comments of mine, each truncated for brevity.
Preferring extremist Republican candidates because they’re easier to beat didn’t work well for the 2016 presidential election. (Yes, Trump did take moderate positions on things like SS privatization, but he also introduced extreme positions and language on immigration.)...
If DeSantis runs for president in 2024, I don’t think his policy positions will be that important. Instead, his fight with Trump in the Republican primary will be the defining feature. …
These anti-rule-encorcement leftists would be better served with some sort of libertarian or anarchist political allegiance. It’s a shame that the American Libertarian organizations have gone so far off the rails…
These three comments all appear to be related to electoral politics and political parties. Let us contrast those against some of my comments from the smallest cluster, index 14.
Yep. I sometimes opine that there is a hawkish/right-wing-ish argument for moving away from fossil fuels since it weakens the position of many of our enemies and frenemies. …
A carbon tax and dividend sounds great in theory because it addresses the regressive distributional issues. …
Are the induced demand critics of highway widening actually opposing this as a climate policy aim or simply stating that the widening doesn’t reduce traffic? …
These three comments appear related to climate change and related policies.
We could continue this approach for each cluster (and include comments from other subscribers) to manually assign a title to each cluster. But that would be tedious and prone to human bias. Eg, I might choose to focus on some subset of comments in each group that address pet issues of my own.
Instead, we can use ChatGPT to suggest cluster titles by giving it a sample of comments from each cluster. After some experimentation, I found that the following prompt produced consistently useful results.
Suggest one to four categories that the following comments have in common, formatted as a Python list:
[15 example comments from the cluster]
For the largest cluster, index 0, ChatGPT suggests: ['politics', 'parties', 'messaging', 'media']. Whereas for the smallest cluster, index 14, it gives: ['Climate change', 'Energy', 'Policy', 'Technology']. Those are consistent with the themes that we manually identified by inspecting a sample of my comments from each of the two clusters.
Repeating this prompt for all clusters, using the OpenAI Chat Completion API (gpt-3.5-turbo), gives us a label for each. The results give us some insights into topics discussed on this substack, and the relative frequency of comments from each topic. (Ie, the figure at the start of this post.)
We can also use these clusters to analyze subscriber sentiment of comments from each category. Specifically, we can compute the distribution of likes-per-a-comment for each cluster as shown using a box plot in the following figure.

Here we see that “Controversial Social Issues” comments are a subscriber favorite, averaging roughly 7 likes for each comment. In contrast, the “Political Systems, Electoral Processes” comments only average 3.9 likes.
Lastly, we can use these comment clusters to quantify the topics discussed by a single user and contrast that to the broader subscriber base. For example, here is the distribution of comment categories for my comments relative to all comments.

We see that I’m more likely to discuss “Politics, Media, Social Issues, Technology” issues than the average subscriber, and less likely to discuss “COVID measures and vaccines”.
Overall, I’m quite impressed with the quality of labeled clusters generated using OpenAI’s models. I had previously experimented with more conventional embedding techniques like word frequencies, and the results were quite disappointing. Further, it was trivial for me to apply these APIs. There was no need to experiment with feature engineering nor dimensional reduction. Lastly, it was cheap. I barely spent $1.00 on API calls for embeddings and chat completions.
So I’m definitely excited to keep playing with OpenAI’s on-demand intelligence to make sense of text. Check back soon for some analysis of the comments from other substacks that I subscribe to so that we can compare the topics discussed in different subscriber communities.
Appendix
For k-means clustering it is necessary to specify the number of clusters ahead of time. Eg, we could compute 5 or 20 clusters instead of the chosen 15. So how is 15 selected?
This is determined by running clustering across a range of different cluster count values. For each count, cluster quality is quantified using the Silhouette Score, a measure of how similar cluster members are relative to non-members. Higher values correspond to higher quality clusters.
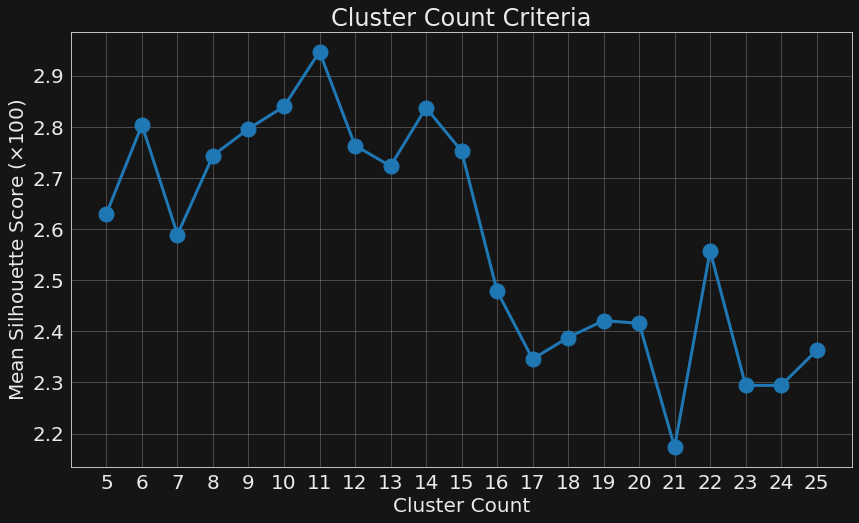
We see that this cluster quality metric falls off rapidly after 15. Hence that value is chosen to give the largest number of topics without degrading clustering quality.
whathca found matt